Reflexion: Verbal Reinforcement Learning 🧠
Master the framework that reinforces language agents through linguistic feedback, enabling them to learn from past mistakes without the need for model fine-tuning.
This content is adapted from Prompting Guide: Reflexion. It has been curated and organized for educational purposes on this portfolio. No copyright infringement is intended.
Introduction
Standard language agents often struggle to improve their performance without extensive retraining. Reflexion, proposed by Shinn et al. (2023) (opens in a new tab), is a new paradigm for "verbal" reinforcement that parameterizes a policy as an agent's memory encoding.
At a high level, Reflexion converts environmental feedback into linguistic feedback—self-reflection—which is then provided as context for the agent in its next attempt.
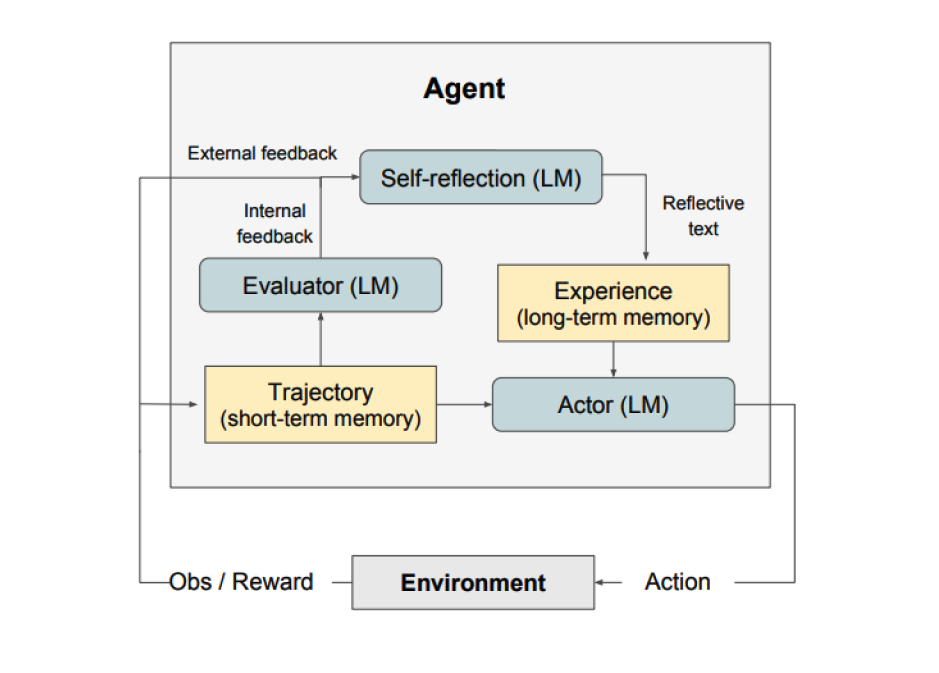 Image Source: Shinn et al. (2023)
Image Source: Shinn et al. (2023)
The Tripartite Architecture
Reflexion consists of three distinct models working in tandem:
- The Actor: Generates text and actions based on observations. Core models like Chain-of-Thought (CoT) or ReAct serve as the Actor.
- The Evaluator: Scores the Actor's outputs by taking a generated trajectory and outputting a reward score (binary or scalar).
- Self-Reflection: An LLM that generates verbal reinforcement cues based on the reward signal, current trajectory, and persistent memory.
How Reflexion Learns
The Reflexion process follows a cyclical, iterative path:
- Define Task → Generate Trajectory → Evaluate → Reflect → Repeat.
This feedback loop allows the agent to rapidly and effectively learn from prior mistakes, leading to state-of-the-art performance on various complex tasks.
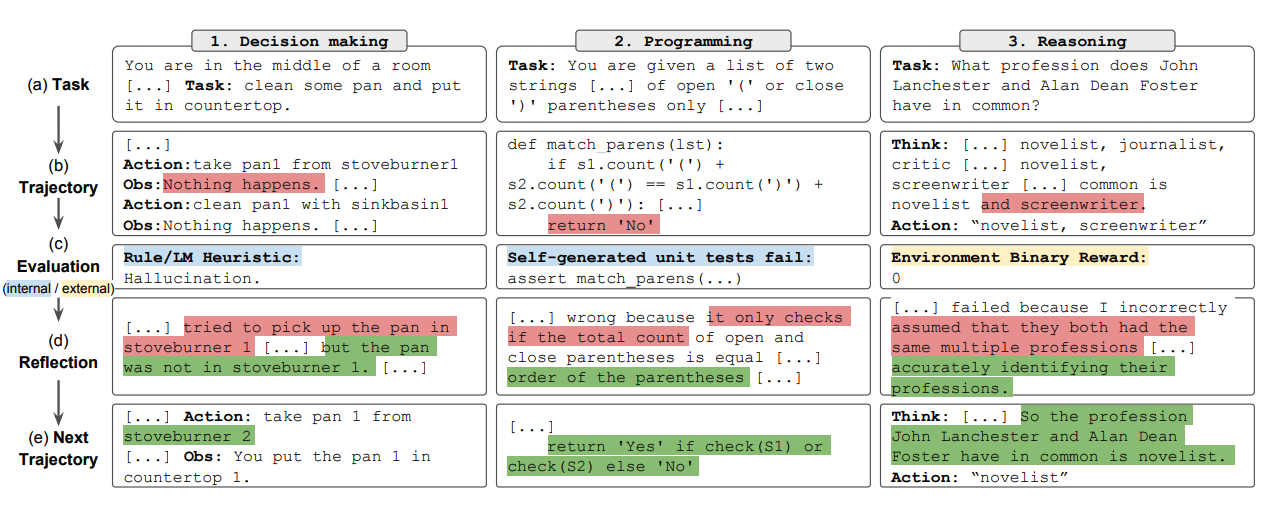 Image Source: Shinn et al. (2023)
Image Source: Shinn et al. (2023)
Research Results
Experimental results show that Reflexion agents significantly outperform traditional few-shot and CoT baselines across decision-making, reasoning, and programming tasks.
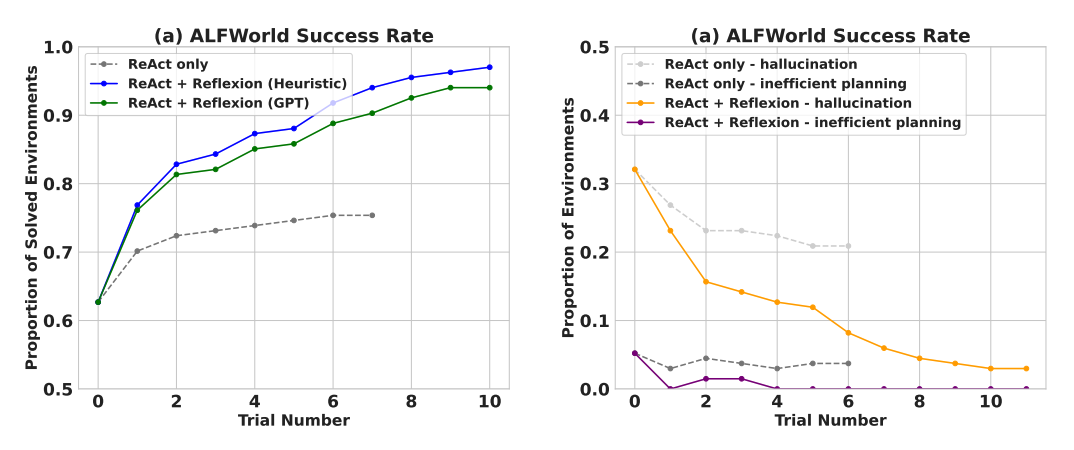
Sequential Decision-Making (ALFWorld)
On ALFWorld tasks, ReAct + Reflexion completed 130 out of 134 tasks, significantly outperforming standalone ReAct.
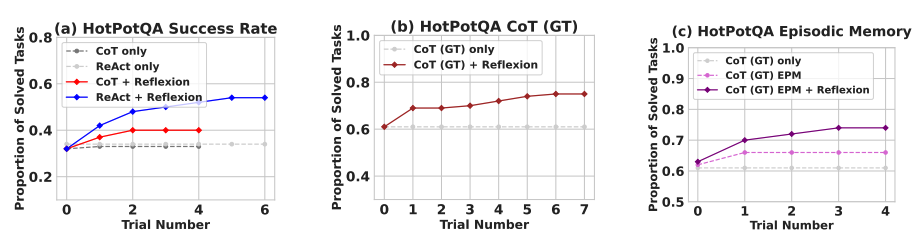
Complex Reasoning (HotPotQA)
Reflexion + CoT consistently outperforms CoT only and CoT with episodic memory by leveraging persistent self-reflection.
Programming (HumanEval & MBPP)
Reflexion achieved state-of-the-art results on Python and Rust code writing benchmarks, outperforming previous SOTA approaches on HumanEval (opens in a new tab).

When to Use Reflexion?
Reflexion is best suited for scenarios where:
- Trial and Error is Necessary: Environments like ALFWorld or WebShop.
- Fine-tuning is Impractical: High compute costs or limited training data.
- Nuanced Feedback is Required: Verbal feedback is more specific than scalar rewards.
- Interpretability is Key: Self-reflections are stored in explicit memory, making the learning process human-readable.
Limitations: Reflexion relies heavily on the agent's ability to accurately self-evaluate. For extremely complex tasks, persistent memory may require more advanced structures like vector databases or SQL.
[!TIP] Reflexion is a major step toward autonomous systems that can debug themselves. To see how these self-correcting loops can be applied to multi-modal reasoning, explore Multimodal CoT next.