Multimodal Chain-of-Thought (CoT) 👁️
Explore the two-stage framework that incorporates text and vision modalities into a single reasoning trace, allowing smaller models to outperform GPT-3.5 on complex scientific benchmarks.
This content is adapted from Prompting Guide: Multimodal CoT. It has been curated and organized for educational purposes on this portfolio. No copyright infringement is intended.
Introduction
Traditional Chain-of-Thought (CoT) prompting has primarily focused on the language modality. However, humans often use multiple senses to solve problems. Multimodal CoT, proposed by Zhang et al. (2023) (opens in a new tab), brings visual and textual reasoning into a unified framework.
This approach uses a two-stage process to bridge the gap between perception and logic.
The Two-Stage Framework
Instead of jumping straight to an answer, Multimodal CoT breaks the problem-solving process into two distinct phases:
- Rationale Generation: The model takes multimodal information (both image and text) and generates a detailed rationale. This phase helps the model "understand" the context by first articulating the reasoning.
- Answer Inference: The model leverages the generated rationale to infer the final, accurate answer.
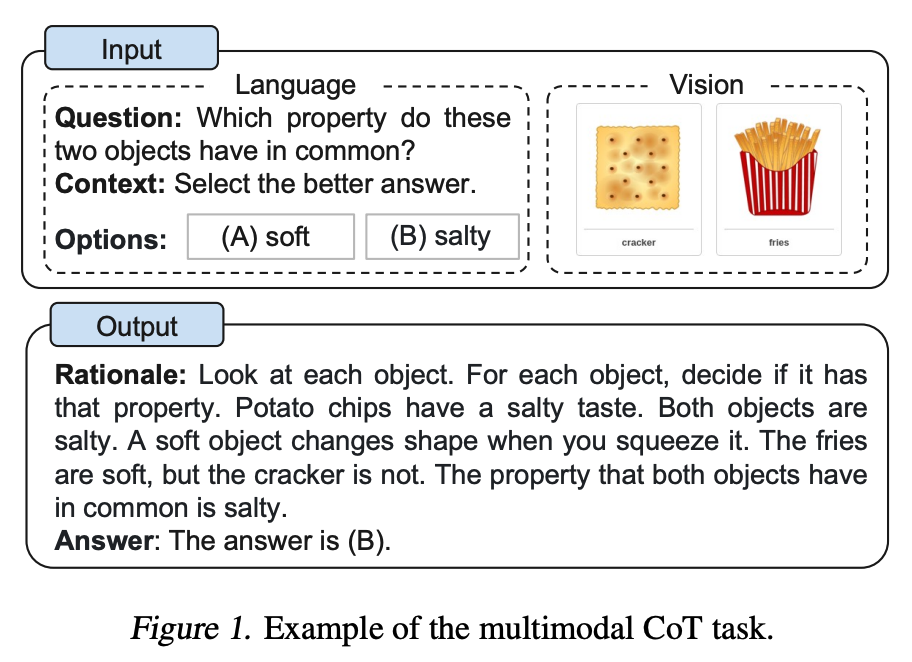 Image Source: Zhang et al. (2023)
Image Source: Zhang et al. (2023)
State-of-the-Art Results
Multimodal CoT demonstrates that model size isn't everything. A 1B-parameter model using this framework was able to outperform GPT-3.5 on the ScienceQA benchmark, showcasing the power of structured multimodal reasoning.
Furthermore, research indicates that aligning perception with language models—treating "vision" as an additional input modality for CoT—leads to more robust and accurate scientific reasoning.
ScienceQA Success: The ScienceQA benchmark consists of 21,208 multimodal multiple-choice questions with diverse topics across three subjects: natural science, social science, and language science.
[!TIP] To see how these multimodal patterns evolve into fully autonomous loops, explore the ReAct Framework or Reflexion to understand how agents can interact with dynamic environments.