Retrieval Augmented Generation (RAG) for LLMs 📚
Master the evolution from Naive to Modular RAG. Explore advanced retrieval paradigms, evaluation metrics, and the latest research on bridging the gap between static model weights and dynamic external knowledge.
This content is adapted from Prompting Guide: RAG Research. It has been curated and organized for educational purposes on this portfolio. No copyright infringement is intended.
Introduction
Working with LLMs presents several challenges: domain knowledge gaps, factuality issues, and hallucinations. Retrieval Augmented Generation (RAG) provides a robust solution by augmenting LLMs with external knowledge bases.
A key advantage of RAG is that the LLM doesn't need to be retrained for task-specific applications, allowing it to access continually updating information.
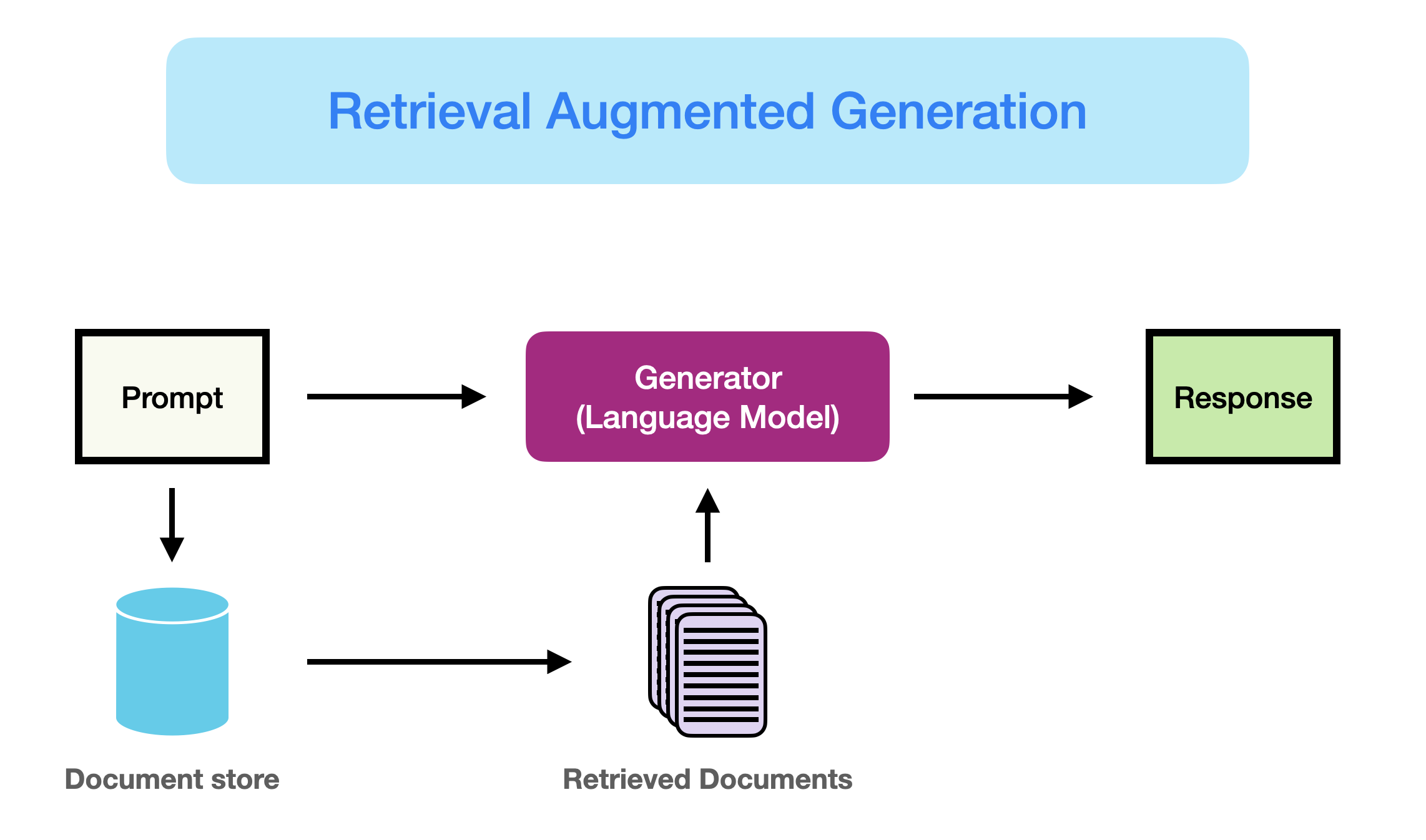 Image Source: Gao et al. (2023)
Image Source: Gao et al. (2023)
RAG Paradigms: The Evolution
Over the past few years, RAG systems have evolved from simple implementations to complex, modular architectures to address limitations in performance, cost, and efficiency.
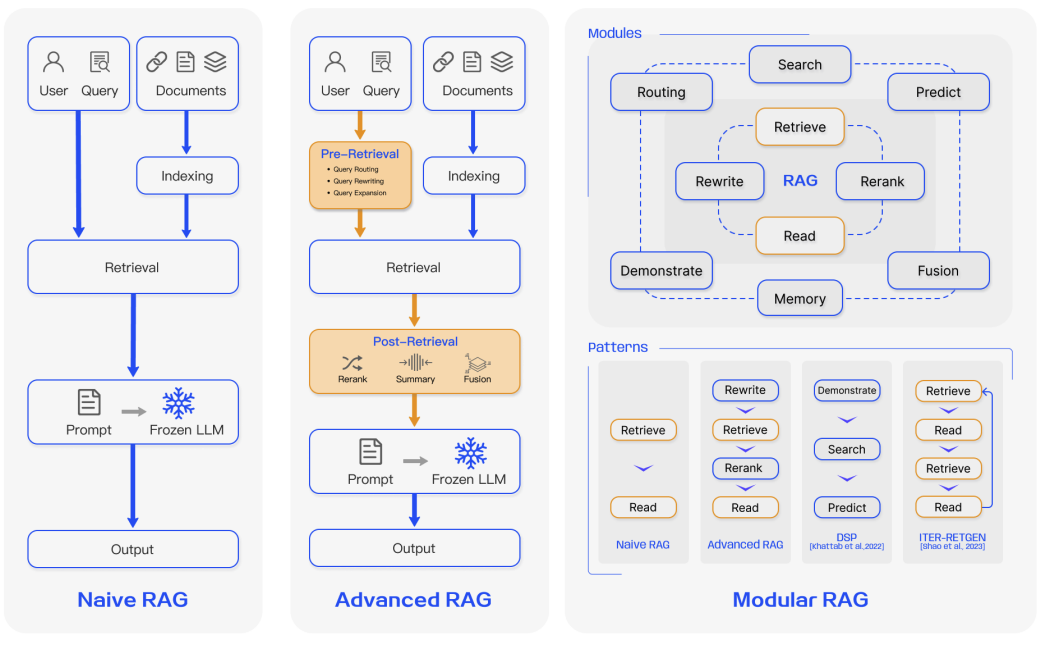 Image Source: Gao et al. (2023)
Image Source: Gao et al. (2023)
1. Naive RAG
The traditional process of Indexing → Retrieval → Generation. While effective, it suffers from low precision (misaligned chunks) and low recall (failure to retrieve all relevant info).
2. Advanced RAG
Optimizes pre-retrieval and post-retrieval processes.
- Pre-retrieval: Enhancing data granularity and optimizing index structures.
- Post-retrieval: Using reranking to prioritize the most relevant context and prompt compression to fit within window limits.
3. Modular RAG
The most flexible paradigm, incorporating specialized modules for search, memory, fusion, and routing. These can be rearranged based on specific task requirements, offering greater diversity and reliability.
The RAG Framework
A modern RAG system is built on three core pillars: Retrieval, Generation, and Augmentation.
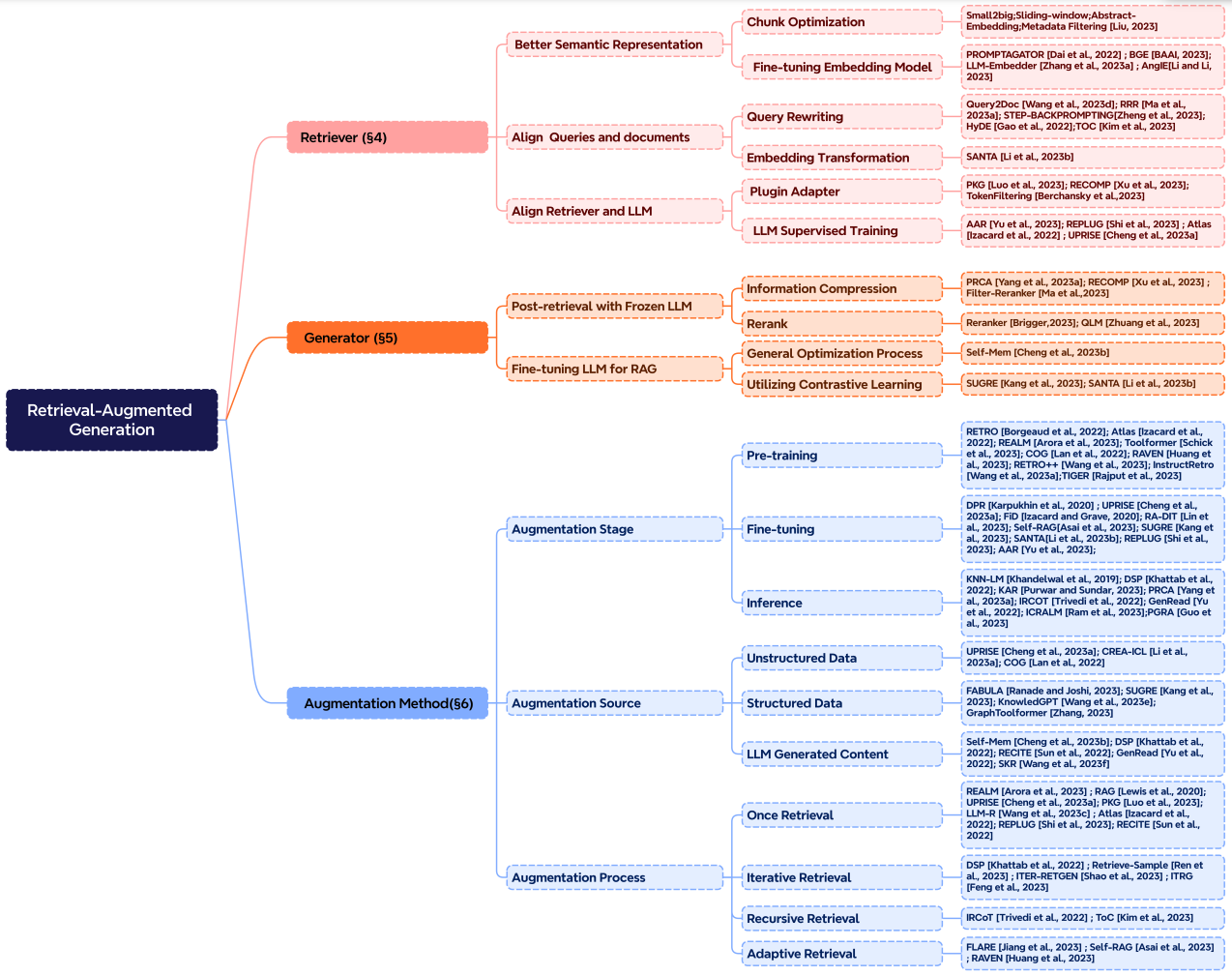 Image Source: Gao et al. (2023)
Image Source: Gao et al. (2023)
Retrieval
Focuses on aligning user queries with document chunks in semantic space.
- Chunking Strategy: choosing the right token size (e.g., 256 vs 512) for the specific embedding model.
- Query Rewriting: Techniques like HyDE (Hypothetical Document Embeddings) generate a fake answer first to improve retrieval relevance.
Generation
The goal is to convert retrieved snippets into coherent, grounded text.
- Frozen LLM: Using a powerful model like GPT-4 to synthesize information.
- Fine-tuned Generator: Optimizing the model specifically to handle and cite retrieved documents.
Augmentation Process
- Iterative Retrieval: Multiple cycles to enhance depth.
- Recursive Retrieval: Using the output of one step as the query for the next (ideal for legal or academic research).
- Adaptive Retrieval: Determining the optimal moments to retrieve context based on model confidence (e.g., FLARE).
RAG vs. Fine-tuning
A common question is whether to use RAG or fine-tune. Research suggests they are complementary:
- RAG is superior for integrating new, quickly-evolving knowledge.
- Fine-tuning is better for teaching the model a specific format, tone, or complex instruction-following.
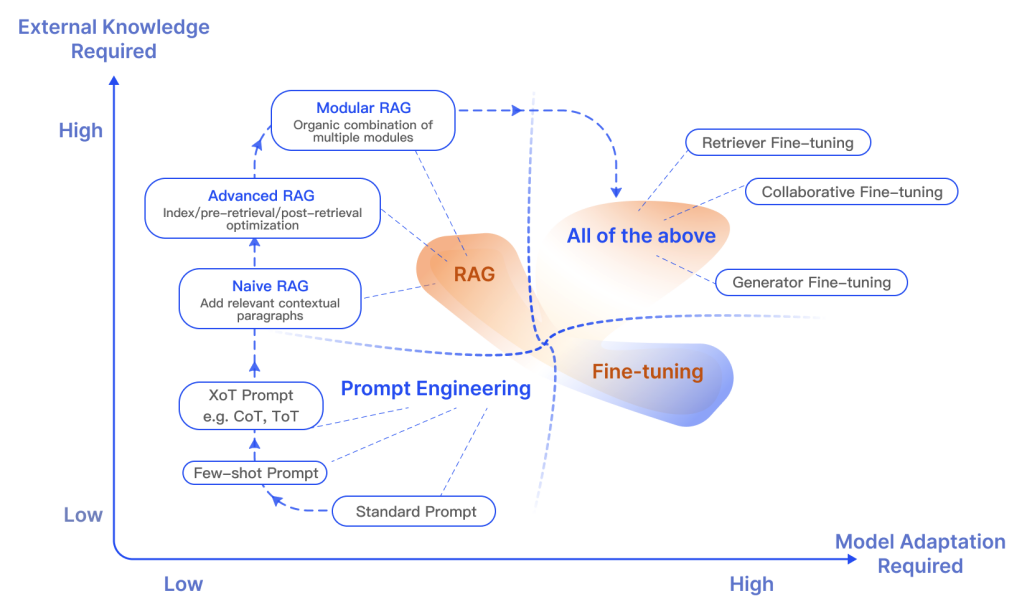 Image Source: Gao et al. (2023)
Image Source: Gao et al. (2023)
Evaluating RAG Performance
Evaluating a RAG framework focuses on three primary quality scores, often called the RAG Triad:
- Context Relevance: Is the retrieved context accurate and specific to the query?
- Answer Faithfulness: Is the answer derived only from the retrieved context?
- Answer Relevance: Does the answer directly address the user's question?
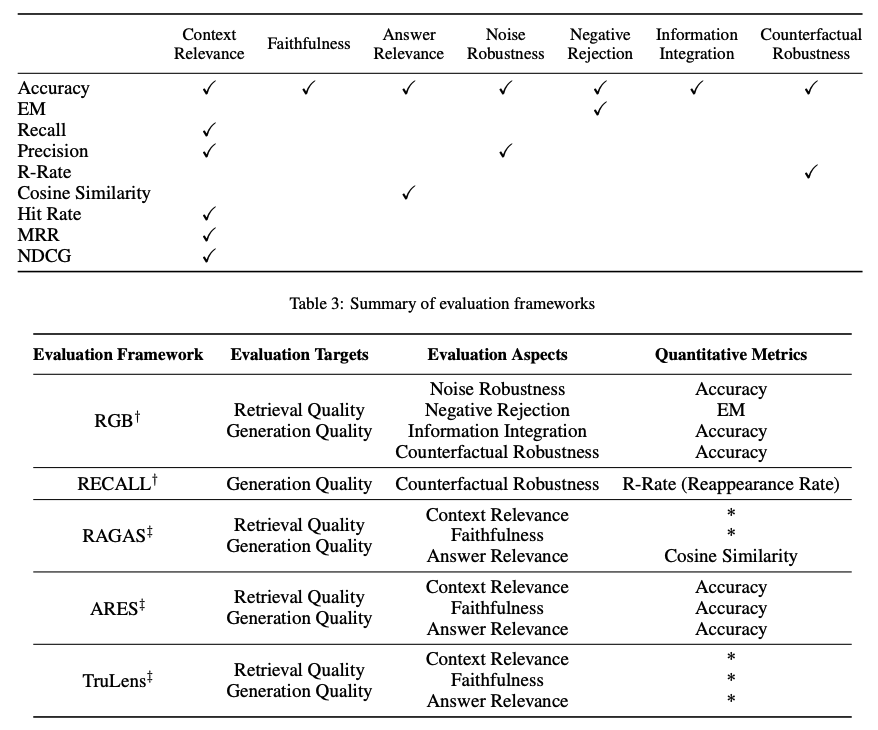 Image Source: Gao et al. (2023)
Image Source: Gao et al. (2023)
Research Insights & Milestones
The following table summarizes key developments in RAG research, from the foundational 2020 Meta AI paper to recent advances in 2024.
| Insight | Reference | Date |
|---|---|---|
| CRAG: Implements a self-correct component for the retriever. | Corrective RAG (opens in a new tab) | Jan 2024 |
| RAPTOR: Recursive abstractive processing for tree-organized retrieval. | RAPTOR (opens in a new tab) | Jan 2024 |
| Self-RAG: Framework to retrieve, generate, and critique through self-reflection. | Self-RAG (opens in a new tab) | Oct 2023 |
| HyDE: Precise zero-shot dense retrieval without relevance labels. | HyDE (opens in a new tab) | Dec 2022 |
| Foundational RAG: The original seq2seq + dense retrieval proposal. | Lewis et al. (opens in a new tab) | May 2020 |
Looking Ahead: Future RAG research is moving toward Multimodal RAG (images, audio, and video retrieval) and improving Context Length utilization for "long-context" LLMs.